

研究方向
大数据应用层
- 应用设计开发层

在目前的数据科学(data science)领域中,R[是一个被广泛采用的统计计算语言。R因其丰富的统计计算功能、友好的交互式用户界面和易于使用的线性代数、数据分析API而深受数据分析师的喜爱。但R语言及其计...详情→
大数据分析算法层
- 综合分析算法层
- 基础算法层

随着信息技术的飞速发展,推荐系统在人们的日常生活中起着重要的作用。尤其是在信息爆炸式增长的当今,人们难以从海量的数据中去寻找自己所需要的个性化信息。因此,研究实现适用于大规模场景的...详情→

随着日益频繁的跨国人文和学术交流,对机器翻译提出了迫切的需求。然而在大规模平行语料数据集下,传统单机统计机器翻译系统模型训练耗时过长,严重制约了统计机器翻译的模型深入研究及其应用推...详情→

科技文献关键词抽取任务是科技文献内容分析中的一项基础任务。通过对科技文献进行关键词抽取,研究人员可以获得语料的中心内容和语义表达,借此进一步完成文本检索、文本分类和聚类等处理任务。...详情→

随着网络和科技的快速发展,电子科技文献呈爆炸式增长。利用数据挖掘和文本分析等技术对科技文献语料进行分析挖掘,研究人员可以发现热点研究领域,了解领域热点研究方向变化,查找相似文献,分...详情→

Cichlid构建在Spark之上,是一个分布式的RDFS/OWL推理系统,相对于现有的基于MapReduce或者P2P自组织网络的分布式推理系统,Cichlid实现了更好的的执行效率和可扩展性...详情→

针对MapReduce分布式并行计算框架对推理算法进行优化‘;克服现有语义推理引擎在可扩展性方面的不足;改善推理系统的执行效率...详情→

子图枚举算法,作为图分析计算中的一种基本算法,在生物化学、生态学以及生物信息学中有着广泛的应用。例如:分子式之间的同构查找、社交网络中的频繁结构共现和描述社会网络的演变等。当前存在的众多...详情→

通用后缀树是一种对序列集合中的所有序列的后缀进行索引形成的数据结构,在诸多领域具有广泛的应用需求。然而,由于其构建过程涉及大量的计算和复杂的I/O,目前尚缺少大数据应用场景下高效可扩展...详情→
在许多数据密集型的科学应用,例如数值计算、数据挖掘、计算物理中,矩阵运算都是一项非常核心的部分,大量应用问题的本质都可以转换成矩阵计算。然而在大数据时代,尚没有很好的对于大规模分布式矩阵运算...详情→

深度学习是一种无监督的特征提取算法,其神经网络的训练过程中涉及大量的矩阵运算,随着数据量的增大, 训练过于耗时。而Intel Xeon Phi是Intel推出的众核平台,非常适合向量运算,同时还有...详情→

频繁项集挖掘是数据挖掘领域最为重要的算法之一,其中,Apriori算法是频繁项集挖掘算法中最为经典的算法。然而,频繁项集挖掘算法不仅是数....详情→
大数据计算层
- 并行计算系统平台
- 并行计算模式


大数据时代,人们普遍地意识到大数据较之于小数据通常隐藏着更多、更深层次的价值与知识,对大数据的分析与挖掘能够获得非常大的社会效益和经济效益。UC Berkeley AMP实验室对现存的大数据机器学习系统,从...详情→
大数据存储层
- 分布式数据库
- 分布式文件系统

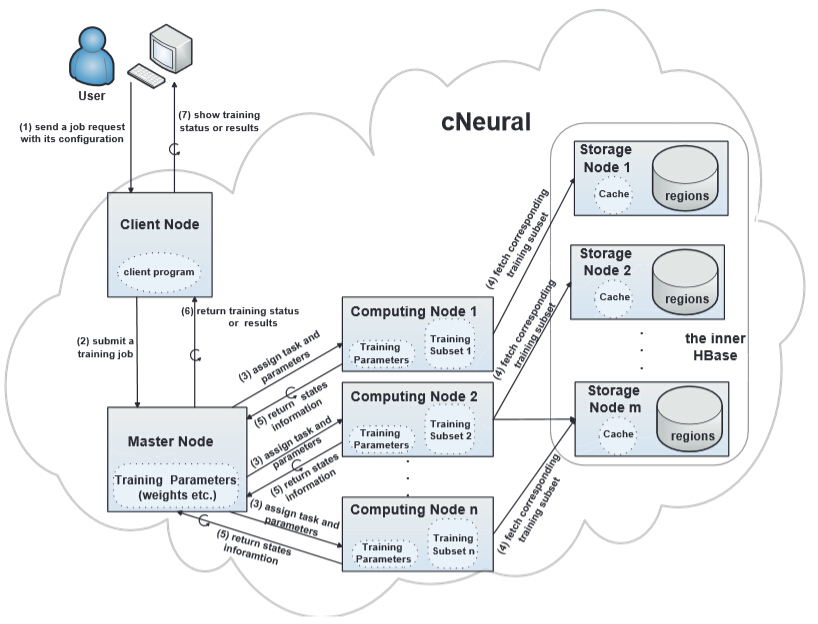
大数据时代,全球数据正以爆炸式的速度增长。为了有效存储和管理海量数据,出现了NoSQL数据库。HBase是一种典型的分布式、面向列的NoSQL数据库,可以对结构化、半结构化、甚至非结构化的海量数据进行实时...详情→
HiBase 是一种采用了分级的索引机制的分布式存储的(原型)系统,可以为HBase中的非主键数据提供索引并加快查询速度。 HiBase使用HBase作为底层存储,并创建了采用热度更新策略的缓存来保存热数据,从而加快了...详情→


目前,很多分布式存储系统以磁盘作为存储介质,严重降低了运行在分布式存储系统上层大数据应用的数据访问效率。因此,有研究者提出了以内存为中心的分布式存储系统,充分利用内存来加速数据访问...详情→
分布式文件系统是大数据生态环境中不可或缺的一部分,是上层计算框架和应用的基石。随着数据量的爆炸式增长,分布式文件系统得到了越来越广泛地使用,同时也出现了一批又一批新的分布式文件系统...详情→

Fluid是一个开源的Kubernetes原生的分布式数据集编排和加速引擎,主要服务于云原生场景下的数据密集型应用,例如大数据应用、AI应用等。通过定义数据集资源的抽象...详情→