
# Fluid 0.3 Release Official: Accelerating data generalization for cloud native scenes

Guidance: In order to solve the painful points of data high access delay, difficult joint analysis, multidimensional management in the separate scenario of data-intensive applications such as big data and AI, etc. In September 1920, Nanjing University PASALab, Alibaba and Alluxio jointly launched Open Source Project Fluid.
Fluid is an efficient support platform for data-intensive applications in the cloud native environment. Since the release of open source, the project has attracted the attention of many interested field experts and engineers, and the development of the community is progressing rapidly with positive feedback from everyone.Recently, Fluid version 0.3 was officially released with three new key features:
Accelerate universal data storage, provide Kubernetes data volume access acceleration
Enhance data access security and provide fine-grained privilege control for datasets
Simplify user complex parameter configuration, provide internal parameter configuration optimization function of biochemical system
Fluid project address:https://github.com/fluid-cloudnative/fluid
The development needs of these three main functions come from the actual production feedback of many community users. In addition, Fluid v0.3 has made some bug fixes and document updates. Welcome to experience Fluid v0.3!Thank you for contributing to this release. We will continue to follow and adopt community recommendations extensively to promote the development of the Fluid project. We look forward to hearing more from you!
Fluid v0.3 Download Link:https://github.com/fluid-cloudnative/fluid/releases
The following is a further description of the new release functionality.
# 1. Supports Kubernetes data volume access acceleration
Although previous versions of Fluid already support many underlying storage systems (such as HDFS, OSS, and so on), in real production environments, enterprise-wide storage systems tend to be more diverse, and the inability to connect to Fluid due to incompatible storage systems still exists.For example, if a user uses the Lustre distributed file system, he or she will not be able to use Fluid properly because the distributed cache engine used by Fluid before is not compatible with the Lustre system.
To improve the versatility of Fluid in cloud native data access acceleration scenarios, Fluid v0.3.Added acceleration support for data volume Persistent Volume Claim (PVC) and host directory (Host Path) to provide a versatile acceleration scheme for linking various storage systems to Fluid, regardless of the underlying storage system used. As long as the storage system can be mapped to a native data volume PVC resource object of Kubernetes or a host directory on a cluster node, it can enjoy the benefits of features such as distributed data caching, data affinity scheduling, and so on through Fluid. The basic concepts are as follows:
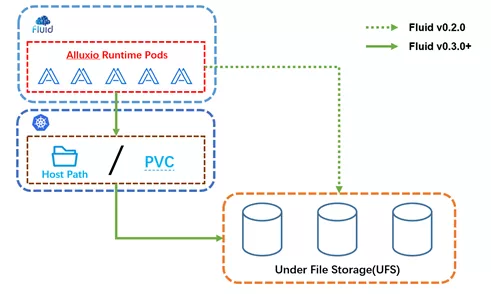
It's easy to use, and the user only needs to specify it in mountPointpvc://nfs-imagenetWhere nfs-imagenet is an existing data volume in the Kubernetes cluster.
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
Name: fluid-imagenet
spec:
mounts:
- mountPoint: pvc://nfs-imagenet
name: nfs-imagenet
This part of the system demonstration video is as follows:
We trained resnet-50 model through tensorflow benchmark as a test scenario to verify the PVC access acceleration ability. The following are the speed improvement results:
| use PVC data volume directly | accelerate PVC data volume with fluid | |
|---|---|---|
| training time | 2h15m59s | 1h43m43s |
| 1000 step speed(images/second) | 3,136 | 8,889 |
| final speed(images/second) | 15,024 | 20,506 |
| Accuracy @ 5 | 0.9228 | 0.9204 |
From the perspective of distributed training, the overall training speed provided by fluid can be reduced by more than 20%. For more test related details, please refer to the relevant sample documents on GitHub:
# 2. Access control of data set
Many enterprises providing machine learning platform services have multi-user shared storage systems and scenarios. For security reasons, machine learning platform service providers need to strictly control access rights to ensure data isolation between users, that is, any unauthorized user shall not access other people's data sets at will.
Fluid provides support for the above scenarios in v0.3: after the underlying storage system shared by multiple users is mounted to fluid, the file permission information exposed by fluid (such as the user, file mode, etc.) will be consistent with the underlying storage system, that is, the transparent transmission of files from the underlying storage system to the node where fluid is deployed is realized. This means that the access control in the underlying storage system will also take effect on each node deploying fluid, so as to ensure that the data isolation between users will not be damaged.
In addition, fluid v0.3 also provides the feature of "temporary borrowing" of datasets“ Temporary borrowing means that a user needs to have temporary access to a dataset of another user. In fluid v0.3, administrators can complete the conversion of dataset ownership on the node where fluid is deployed through flexible configuration, so as to give designated users the ability to "temporarily borrow" other people's datasets, which can help cluster administrators achieve finer grained and flexible data centralized authority management.
usage documents for accessing non root user data
# 3. Default parameter configuration optimization
Fluid provides many parameter configurations for users to customize their own applications. Before fluid version 0.3, users need to manually configure according to the actual environment and business objectives. However, it is difficult and heavy workload for most users to manually complete configuration optimization.
Fluid v0.3 has built-in a large number of default parameter configuration optimization for internal components such as alluxio and fuse. Users no longer need to focus a lot on parameter configuration optimization. According to our experience, the optimized default parameter settings can achieve better performance in most common fluid usage scenarios.
# Summary
Fluid v0.3 mainly solves the problems and needs fed back by community users in the actual production environment. The support of host directory and PVC mount provides a general solution for compatibility with different underlying storage systems; The access control of data sets enables fluid to truly meet the needs of the actual production environment shared by multiple users; The optimized default parameter configuration increases the ease of use of fluid and maintains stable performance in most scenarios.
If you have any questions, please join the nail exchange group to participate and discuss: