
# Fluid 给数据弹性一双隐形的翅膀 -- 自定义弹性伸缩

导读: 弹性伸缩作为 Kubernetes 的核心能力之一,但它一直是围绕这无状态的应用负载展开。而 Fluid 提供了分布式缓存的弹性伸缩能力,可以灵活扩充和收缩数据缓存。 它基于 Runtime 提供了缓存空间、现有缓存比例等性能指标, 结合自身对于 Runtime 资源的扩缩容能力,提供数据缓存按需伸缩能力。
# 背景
随着越来越多的大数据和 AI 等数据密集应用开始部署和运行在 Kubernetes 环境下,数据密集型应用计算框架的设计理念和云原生灵活的应用编排的分歧,导致了数据访问和计算瓶颈。云原生数据编排引擎 Fluid 通过数据集的抽象,利用分布式缓存技术,结合调度器,为应用提供了数据访问加速的能力。
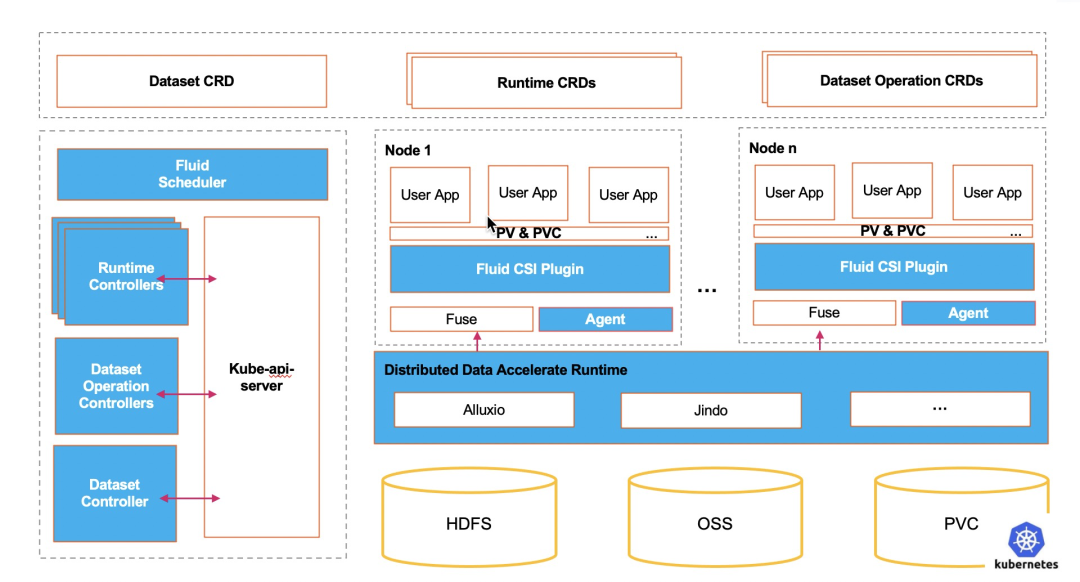
弹性伸缩作为 Kubernetes 的核心能力之一,但它一直是围绕这无状态的应用负载展开。而 Fluid 提供了分布式缓存的弹性伸缩能力,可以灵活扩充和收缩数据缓存。它基于 Runtime 提供了缓存空间、现有缓存比例等性能指标, 结合自身对于 Runtime 资源的扩缩容能力,提供数据缓存按需伸缩能力。
这个能力对于互联网场景下大数据应用非常重要,由于多数的大数据应用都是通过端到端流水线来实现的。而这个流水线包含以下几个步骤:
- 数据提取:利用 Spark,MapReduce 等大数据技术对于原始数据进行预处理。
- 模型训练:利用第一阶段生成特征数据进行机器学习模型训练,并且生成相应的模型。
- 模型评估:通过测试集或者验证集对于第二阶段生成模型进行评估和测试。
- 模型推理:第三阶段验证后的模型最终推送到线上为业务提供推理服务。
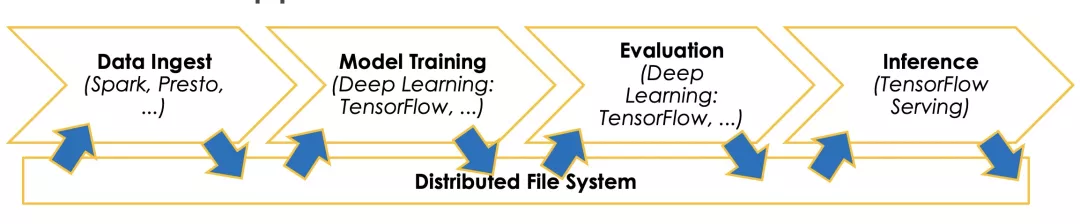
可以看到端到端的流水线会包含多种不同类型的计算任务,针对每一个计算任务,实践中会有合适的专业系统来处理(TensorFlow,PyTorch,Spark, Presto);但是这些系统彼此独立,通常要借助外部文件系统来实现把数据从一个阶段传递到下一个阶段。但是频繁的使用文件系统实现数据交换,会带来大量的 I/O 开销,经常会成为整个工作流的瓶颈。
而 Fluid 对于这个场景非常适合,用户可以创建一个 Dataset 对象,这个对象有能力将数据分散缓存到 Kubernetes 计算节点中,作为数据交换的介质,这样避免了数据的远程写入和读取,提升了数据使用的效率。但是这里的问题是临时数据缓存的资源预估和预留。由于在数据生产消费之前,精确的数据量预估是比较难满足,过高的预估会导致资源预留浪费,过低的预估会导致数据写入失败可能性增高。还是按需扩缩容对于使用者更加友好。我们希望能够达成类似 page cache 的使用效果,对于最终用户来说这一层是透明的但是它带来的缓存加速效果是实实在在的。
我们通过自定义 HPA 机制,通过 Fluid 引入了缓存弹性伸缩能力。弹性伸缩的条件是当已有缓存数据量达到一定比例时,就会触发弹性扩容,扩容缓存空间。例如将触发条件设置为缓存空间占比超过 75%,此时总的缓存空间为 10G,当数据已经占满 8G 缓存空间的时候,就会触发扩容机制。
下面我们通过一个例子帮助您体验 Fluid 的自动扩缩容能力。
# 前提条件
推荐使用 Kubernetes 1.18 以上,因为在 1.18 之前,HPA 是无法自定义扩缩容策略的,都是通过硬编码实现的。而在 1.18 后,用户可以自定义扩缩容策略的,比如可以定义一次扩容后的冷却时间。
# 具体步骤
# 1. 安装 jq 工具方便解析 json
在本例子中我们使用操作系统是 centos,可以通过 yum 安装 jq。
yum install -y jq
# 2. 下载、安装 Fluid 最新版
git clone https://github.com/fluid-cloudnative/fluid.git
cd fluid/charts
kubectl create ns fluid-system
helm install fluid fluid
# 3. 部署或配置 Prometheus
这里通过 Prometheus 对于 AlluxioRuntime 的缓存引擎暴露的 Metrics 进行收集,如果集群内无 prometheus:
$ cd fluid
$ kubectl apply -f integration/prometheus/prometheus.yaml
如集群内有 prometheus,可将以下配置写到 prometheus 配置文件中:
scrape_configs:
- job_name: 'alluxio runtime'
metrics_path: /metrics/prometheus
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_monitor]
regex: alluxio_runtime_metrics
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: web
action: keep
- source_labels: [__meta_kubernetes_namespace]
target_label: namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_label_release]
target_label: fluid_runtime
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_endpoint_address_target_name]
target_label: pod
replacement: $1
action: replace
# 4. 验证 Prometheus 安装成功。
$ kubectl get ep -n kube-system prometheus-svc
NAME ENDPOINTS AGE
prometheus-svc 10.76.0.2:9090 6m49s
$ kubectl get svc -n kube-system prometheus-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-svc NodePort 172.16.135.24 <none> 9090:32114/TCP 2m7s
如果希望可视化监控指标,您可以安装 Grafana 验证监控数据,具体操作可以参考文档。
文档地址:
https://github.com/fluid-cloudnative/fluid/blob/master/docs/zh/operation/monitoring.md
# 5. 部署 metrics server
检查该集群是否包括 metrics-server,执行 kubectl top node 有正确输出可以显示内存和 CPU,则该集群 metrics server 配置正确。
kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
192.168.1.204 93m 2% 1455Mi 10%
192.168.1.205 125m 3% 1925Mi 13%
192.168.1.206 96m 2% 1689Mi 11%
否则手动执行以下命令:
kubectl create -f integration/metrics-server
# 6. 部署 custom-metrics-api 组件。
为了基于自定义指标进行扩展,你需要拥有两个组件:
- 第一个组件是从应用程序收集指标并将其存储到 Prometheus 时间序列数据库。
- 第二个组件使用收集的度量指标来扩展 Kubernetes 自定义 metrics API,即 k8s-prometheus-adapter。
第一个组件在第三步部署完成,下面部署第二个组件。
如果已经配置了custom-metrics-api,在 adapter 的 configmap 配置中增加与 dataset 相关的配置:
apiVersion: v1
kind: ConfigMap
metadata:
name: adapter-config
namespace: monitoring
data:
config.yaml: |
rules:
- seriesQuery: '{__name__=~"Cluster_(CapacityTotal|CapacityUsed)",fluid_runtime!="",instance!="",job="alluxio runtime",namespace!="",pod!=""}'
seriesFilters:
- is: ^Cluster_(CapacityTotal|CapacityUsed)$
resources:
overrides:
namespace:
resource: namespace
pod:
resource: pods
fluid_runtime:
resource: datasets
name:
matches: "^(.*)"
as: "capacity_used_rate"
metricsQuery: ceil(Cluster_CapacityUsed{<<.LabelMatchers>>}*100/(Cluster_CapacityTotal{<<.LabelMatchers>>}))
否则手动执行以下命令:
kubectl create -f integration/custom-metrics-api/namespace.yaml
kubectl create -f integration/custom-metrics-api
注意:因为 custom-metrics-api 对接集群中的 Prometheous 的访问地址,请替换 prometheous url 为你真正使用的 Prometheous 地址。
检查自定义指标:
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "pods/capacity_used_rate",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "datasets.data.fluid.io/capacity_used_rate",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "namespaces/capacity_used_rate",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}
# 7. 提交测试使用的 Dataset
$ cat<<EOF >dataset.yamlapiVersion: data.fluid.io/v1alpha1kind: Datasetmetadata: name: sparkspec: mounts: - mountPoint: https://mirrors.bit.edu.cn/apache/spark/ name: spark---apiVersion: data.fluid.io/v1alpha1kind: AlluxioRuntimemetadata: name: sparkspec: replicas: 1 tieredstore: levels: - mediumtype: MEM path: /dev/shm quota: 1Gi high: "0.99" low: "0.7" properties: alluxio.user.streaming.data.timeout: 300secEOF$ kubectl create -f dataset.yamldataset.data.fluid.io/spark createdalluxioruntime.data.fluid.io/spark created
# 8. 查看这个 Dataset 是否处于可用状态
可以看到该数据集的数据总量为 2.71GiB, 目前 Fluid 提供的缓存节点数为 1,可以提供的最大缓存能力为 1GiB。此时数据量是无法满足全量数据缓存的需求。
$ kubectl get dataset
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
spark 2.71GiB 0.00B 1.00GiB 0.0% Bound 7m38s
# 9. 当该 Dataset 处于可用状态后,查看是否已经可以从 custom-metrics-api 获得监控指标
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/datasets.data.fluid.io/*/capacity_used_rate" | jq
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/datasets.data.fluid.io/%2A/capacity_used_rate"
},
"items": [
{
"describedObject": {
"kind": "Dataset",
"namespace": "default",
"name": "spark",
"apiVersion": "data.fluid.io/v1alpha1"
},
"metricName": "capacity_used_rate",
"timestamp": "2021-04-04T07:24:52Z",
"value": "0"
}
]
}
# 10. 创建 HPA 任务
$ cat<<EOF > hpa.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: spark
spec:
scaleTargetRef:
apiVersion: data.fluid.io/v1alpha1
kind: AlluxioRuntime
name: spark
minReplicas: 1
maxReplicas: 4
metrics:
- type: Object
object:
metric:
name: capacity_used_rate
describedObject:
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
name: spark
target:
type: Value
value: "90"
behavior:
scaleUp:
policies:
- type: Pods
value: 2
periodSeconds: 600
scaleDown:
selectPolicy: Disabled
EOF
首先,我们解读一下从样例配置,这里主要有两部分一个是扩缩容的规则,另一个是扩缩容的灵敏度:
规则:触发扩容行为的条件为 Dataset 对象的缓存数据量占总缓存能力的 90%;扩容对象为
AlluxioRuntime,最小副本数为 1,最大副本数为 4;而 Dataset 和 AlluxioRuntime 的对象需要在同一个 namespace。策略:可以 K8s 1.18 以上的版本,可以分别针对扩容和缩容场景设置稳定时间和一次扩缩容步长比例。比如在本例子, 一次扩容周期为 10 分钟(periodSeconds),扩容时新增 2 个副本数,当然这也不可以超过 maxReplicas 的限制;而完成一次扩容后,冷却时间(stabilizationWindowSeconds)为 20 分钟;而缩容策略可以选择直接关闭。
# 11. 查看 HPA 配置, 当前缓存空间的数据占比为 0。远远低于触发扩容的条件。
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
spark AlluxioRuntime/spark 0/90 1 4 1 33s
$ kubectl describe hpa
Name: spark
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Wed, 07 Apr 2021 17:36:39 +0800
Reference: AlluxioRuntime/spark
Metrics: ( current / target )
"capacity_used_rate" on Dataset/spark (target value): 0 / 90
Min replicas: 1
Max replicas: 4
Behavior:
Scale Up:
Stabilization Window: 0 seconds
Select Policy: Max
Policies:
- Type: Pods Value: 2 Period: 600 seconds
Scale Down:
Select Policy: Disabled
Policies:
- Type: Percent Value: 100 Period: 15 seconds
AlluxioRuntime pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from Dataset metric capacity_used_rate
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events: <none>
# 12. 创建数据预热任务
$ cat<<EOF > dataload.yaml
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: spark
spec:
dataset:
name: spark
namespace: default
EOF
$ kubectl create -f dataload.yaml
$ kubectl get dataload
NAME DATASET PHASE AGE DURATION
spark spark Executing 15s Unfinished
# 13. 此时可以发现缓存的数据量接近了 Fluid 可以提供的缓存能力(1GiB)同时触发了弹性伸缩的条件
$ kubectl get dataset
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
spark 2.71GiB 1020.92MiB 1.00GiB 36.8% Bound 5m15s
从 HPA 的监控,可以看到 Alluxio Runtime 的扩容已经开始, 可以发现扩容的步长为 2。
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
spark AlluxioRuntime/spark 100/90 1 4 2 4m20s
$ kubectl describe hpa
Name: spark
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Wed, 07 Apr 2021 17:56:31 +0800
Reference: AlluxioRuntime/spark
Metrics: ( current / target )
"capacity_used_rate" on Dataset/spark (target value): 100 / 90
Min replicas: 1
Max replicas: 4
Behavior:
Scale Up:
Stabilization Window: 0 seconds
Select Policy: Max
Policies:
- Type: Pods Value: 2 Period: 600 seconds
Scale Down:
Select Policy: Disabled
Policies:
- Type: Percent Value: 100 Period: 15 seconds
AlluxioRuntime pods: 2 current / 3 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 3
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from Dataset metric capacity_used_rate
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: Dataset metric capacity_used_rate above target
Normal SuccessfulRescale 6s horizontal-pod-autoscaler New size: 3; reason: Dataset metric capacity_used_rate above target
# 14. 在等待一段时间之后发现数据集的缓存空间由 1GiB 提升到了 3GiB,数据缓存已经接近完成
$ kubectl get dataset
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
spark 2.71GiB 2.59GiB 3.00GiB 95.6% Bound 12m
同时观察 HPA 的状态,可以发现此时 Dataset 对应的 runtime 的 replicas 数量为 3, 已经使用的缓存空间比例 capacity_used_rate 为 85%,已经不会触发缓存扩容。
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
spark AlluxioRuntime/spark 85/90 1 4 3 11m
# 15. 清理环境
skubectl delete hpa spark
kubectl delete dataset spark
# 总结
Fluid 提供了结合 Prometheous,Kubernetes HPA 和 Custom Metrics 能力,根据占用缓存空间的比例触发自动弹性伸缩的能力,实现缓存能力的按需使用。这样能够帮助用户更加灵活的使用通过分布式缓存提升数据访问加速能力,后续我们会提供定时扩缩的能力,为扩缩容提供更强的确定性。
Fluid 的代码仓库:https://github.com/fluid-cloudnative/fluid.git, 欢迎大家关注、贡献代码和 star。