
# Fluid - efficient "data logistics system" in cloud native environment

Thanks to the advantages of low computing cost, easy expansion, convenient deployment and efficient operation and maintenance, cloud computing platform has attracted more and more data intensive applications to run on it. Today, the cloud native architecture represented by kubernetes is widely used in many data intensive scenarios such as AI / big data because of its flexible resource loadability and efficient application scheduling. However, there are natural differences between cloud native environment and data intensive application computing framework in previous design concepts and mechanisms. Therefore, how to help data intensive applications access data efficiently, safely and conveniently in the cloud native scenario is an important issue with both theoretical significance and application value.
In order to solve the pain points such as high data access delay, difficult joint analysis and complex multi-dimensional management of data intensive applications such as big data and AI in the scenario of separation of cloud native computing and storage, pasalab, Alibaba and alluxio of Nanjing University jointly launched the open source project fluid in September 2020. Fluid is essentially an efficient support platform for data intensive applications in the cloud native environment. This article will introduce how the fluid project runs data intensive applications more efficiently in the k8s environment.
# Project background introduction
# 1. Technological development background
Over the past decade, technologies such as cloud computing, big data and artificial intelligence have developed by leaps and bounds.
cloud computing platform field: the container represented by docker and kubernetes and its choreographed cloud native technology have made great progress in the wave of automatic operation and maintenance of application service deployment.
big data processing field: big data parallel computing and distributed storage technology represented by Hadoop, spark and alluxio has almost formed a mainstream ecology in the application of big data processing and storage in many industries.
artificial intelligence framework field: famous AI training frameworks such as pytorch, tensorflow and Caffe are increasingly mature in the repeated use and participation of AI application developers.
Among them, big data applications and AI applications usually need to carry out calculation and analysis around large-scale data, which are typical data intensive applications. Cloud computing platform has attracted more and more data intensive applications to deploy and run on it due to its advantages of computing cost and easy scale expansion, as well as the advantages of containerization in efficient deployment and agile iteration.
The integration of big data applications, AI and cloud computing is becoming the next important development trend. Gartner predicts that by 2023, more than 70% of AI workloads will be deployed and run in the way of application container, and then built in the cloud native environment through the serverless programming model. Spark version 3.0.1 also supports kubernetes scheduler to embrace the cloud native environment.
- See Gartner report for details:https://www.gartner.com/en/conferences/emea/data-analytics-switzerland/featured-topics/topic-ai-machine-learning
Spark3.0.1 runs on K8s:https://spark.apache.org/docs/latest/running-on-kubernetes.html
# 2. Problems faced
From the actual experience of users, the existing cloud native orchestration framework is not friendly enough to support data intensive applications, which is mainly reflected in low operation efficiency and complex data management.
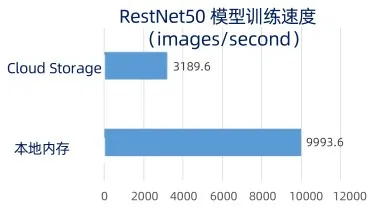
Inefficient operation: as shown in the above figure, a restnet50 neural network can be trained. If it runs based on local memory, it can train nearly 10000 pictures per second; However, running in the cloud native environment, the pictures trained per second based on cloud storage architecture can only reach about 3000 / s, and the performance degradation is obvious. Complex data management:the variability of data versions, the diversity of data interfaces, the abstraction of data types and the heterogeneity of data storage all pose challenges to the support of data intensive applications in the cloud native environment.
# 3. Cause analysis of the problem
There are natural differences in design concepts and mechanisms between cloud native environment and data intensive processing framework. The early generation and development process of these two technologies are independent of each other. We can see that in order to take into account the flexibility and cost of resource expansion, the basic architecture ofseparation of computing and storage is popular in the cloud native environment; In contrast, for the data intensive application framework represented by big data and AI training, in order to reduce data transmission, the design concept needs to considerdata localization architecture. There are differences in the design between the two.

In addition, we found that in the cloud native environment, applications are usually deployed in the way of stateless micro service, and connected in series through FAAS (function as a service). In data intensive framework applications, it is carried out with data abstraction as the center and task allocation and execution. For example, in spark, the whole big data processing application is built around RDD, with operators in the middle. However, stateless microservices are not data centric, which also has design differences.

The above problems lead to the fact that the cloud native orchestration framework represented by kubernetes is not friendly enough to support data intensive applications, especially AI and big data applications, which is specifically reflected in the low operation efficiency and complex data operation management mentioned above.
\We look at the panorama of the cloud native Foundation (CNCF) before the emergence of fluid, covering all aspects from application delivery, operation and maintenance management to underlying storage, but lack the important puzzle of data efficient support components (Note: fluid has just entered the CNCF panorama recently, which reflects that the concept of this article has been recognized). However, the lack of this puzzle will cause big data intensive applications to face technical challenges in terms of inefficient data access, weak data isolation and complex joint access of multiple data sources when running in the cloud native environment.
# 4. Data support challenges in cloud native environment
Specifically, the challenges of data support in the cloud native environment are mainly divided into three aspects:
First:the separation architecture of cloud platform computing and storage leads to high data access latency. In order to monitor resource flexibility and meet the requirements of local non dependency, cloud native applications mostly adopt the separation architecture of computing and storage. However, from the perspective of access efficiency, cloud network transmission bandwidth is required. When data intensive applications run on the cloud, it will cause data access bottlenecks and performance degradation.
Second:joint analysis across storage systems in hybrid cloud scenario is difficult. Most companies / organizations usually support diversified applications based on different storage management data and have their own characteristics. CEPH, glusterfs and HDFS will be widely used, and data will usually be scattered in these heterogeneous storage. However, when combined data is needed for comprehensive analysis, it will increase the cost of data movement, which will inevitably lead to complex problems such as network cost, waiting delay, manual operation and so on.
Third:data security governance and multi-dimensional management in cloud environment are complex. Data is the lifeline of many companies. Data leakage, misoperation and improper life cycle management will cause huge losses. There are great challenges in how to ensure data isolation in the cloud native environment and protect the user's data life cycle.
# 5. A missing piece of abstraction in kubernetes ecology
To sum up, we can summarize a phenomenon: kubernetes ecology currently lacks the puzzle of efficient support for data intensive applications. The existing kubernetes environment can well Abstract many resources, including resource object computing into pod, storage into PV / PVC, and network into service. There are also some storage abstractions in the cloud native domain, which mainly work for data persistence and provide persistent storage management of objects and files. However, the functions of these software lack application-centered data abstraction and related life cycle management.
# 6. Association of store shopping model evolution
In order to better understand these problems, we can do some associative thinking. As shown in the figure below, by introducing the commodity shopping mode, we comparecommodities, supermarkets and customers todata, storage and application.

goods and datawill be consumed, goods will be purchased by consumers, and data will be read by applications. They are similar to each other.
The supermarket and storage are similar in that they both serve the functions of storage and supply. Commodities are usually stored on supermarket shelves and play a role of supply when purchased; For storage, the data we usually store will be persisted to the storage device and provided to users when the application needs it.
customer is similar to application. Customers will go to the store to buy goods. Similarly, the application will store and read data.
Commodities, supermarkets (shops) and customer model have developed very mature and stable in the past few thousand years. Until 2000, there was a disruptive change, which is the emergence of e-commerce. E-commerce has invented the online shopping mode, which is characterized by no longer taking the store as the center, but taking the customer as the center. The goods are stored in the warehouse. Customers can select the goods in the online virtual shop, and finally deliver the goods to customers by modern logistics. The transaction process isefficient and convenient, and the transaction volume is larger. The goods are directly placed in the warehouse, which can be managed in a standardized and independent way. After that, it will be very convenient and convenient for customers to buy goods on the e-commerce platform. Customers do not need to go to stores. They can use mobile phones and computers to shop on the subway, in the car, in the office and at home, and there will be no inefficient commodity search, because customers shop on the Internet and can search a large number of commodities through retrieval; Another advantage of online shopping is that the transaction frequency becomes higher and the transaction volume becomes larger; Customers don't have to go to the store to pick up the goods. Express delivery can be delivered directly to the door, which is very convenient.

There are many factors in the success of the electricity supplier mode. There are two key factors. First, the emergence of the third party digital payment tools such as Alipay, and two, such as rookie, are the logistics system that produces specialized products. In contrast, in the current computer system, under the modern Cloud Architecture, data is stored in the cloud storage system, and data intensive applications also run in the cloud native environment in the form of various resource descriptors such as pod, but there is a lack of an efficient way of data delivery and data delivery. In other words, under the cloud native architecture, the data is stored in the cloud storage system, and the application still accesses the data as needed. However, due to the lack of similar data "logistics system", the consumption and access data of data intensive applications is inefficient on the cloud platform.

# Fluid core philosophy
Based on the above analysis and the association obtained from observation, let's introduce the core concept of fluid.
# 1. Fluid plays the role of cloud native "data logistics system"
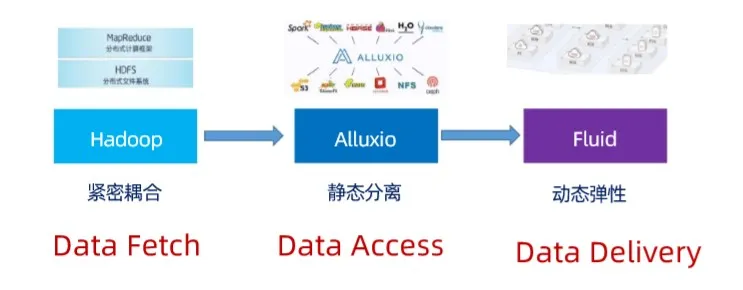
We can understand the role of fluid as a "data logistics system" in the cloud native environment. Recall that in previous big data platforms, data access was done through localization as much as possible. When a user writes a MapReduce job, the job contains many tasks, of which maptask pays more attention. When processing data, the user tries to schedule the task to the node where the data to be processed is located. In this case, when users access data, although the data is in the distributed system HDFS, it is essentially equivalent to obtaining it from the local node in the distributed system, which is called data fetch.
With the rapid development of big data ecosystem, there are more and more application frameworks on it, and the underlying storage systems are becoming richer and richer. The pain point of various upper applications to access different types and diversified systems is becoming more and more obvious. Therefore, there is an excellent open source project such as alluxio to uniformly manage different underlying storage systems, Provide a unified standard interface for the upper layer, and shield the differences of different storage for the upper layer applications. Moreover, alluxio provides memory cache to speed up data access. This process decouples the localization, and the storage can be separated. This separation architecture is usually static after deployment, which realizes the process from data fetch to data access.
Based on alluxio, fluid makes further research and expansion on the scheduling level of the cloud native environment, hoping to obtain the dynamic change information of data nodes and applications in the cloud native environment, so as to dynamically and flexibly mobilize this kind of static cache and other middleware, so as to make the application more flexible and realize the effect of intelligent data delivery to applications, That is, dynamic elasticity (data delivery).
During project design, we hope fluid will bring some innovations from three levels: perspective, idea and concept:
new perspective : re comprehensively examine the data abstraction and access support of cloud native scenarios from two aspects: the combination of cloud native resource scheduling and data intensive processing.
new ideas : Aiming at the lack of data perception of container orchestration and the lack of perception of architecture changes on the cloud, a series of concepts and innovative methods of collaborative orchestration, multi-dimensional management and intelligent perception are proposed; So as to form an efficient support platform for data intensive applications in the cloud native environment.
new concept : through the fluid project, it is hoped that data can be accessed, transformed and managed flexibly and efficiently in the cloud platform and between the resource arrangement layer and the data processing layer.
# 2. Core concept
In short, the core concept of fluid can be divided into "one abstraction" and "two choreography".
Firstly, in the cloud native environment, the concept of data set is abstracted. It can provide a package for the underlying storage and various support and access capabilities for the upper layer, so as to simply operate the data under k8s through API.
On this basis, fluid provides two choreography capabilities: The first is to arrange the data set, which specifically refers to the arrangement based on the data of container scheduling management. The traditional method only manages the data itself, while the data set arrangement of fluid changes to the arrangement and management of the engine carrying the data. Through reasonable capacity expansion, capacity reduction and scheduling of the data engine and interaction with the data engine, the management and change of data migration, caching and flexible scheduling of data under k8s platform can be realized.
The second choreography is the choreography of applications that use and consume such data sets. We need to handle the scheduling of these applications and make them aware of the cache data set as much as possible, so that we can reasonably select nodes when scheduling applications, so as to carry out relevant calculations efficiently.
In summary, fluid has the following three functions:
# 1) provide native support for cloud platform dataset abstraction
The basic support capabilities required for data intensive applications are functionalized to achieve efficient data access and reduce multidimensional costs.
# 2) data set arrangement based on container scheduling management
Through the cooperation of dataset caching engine and kubernetes container scheduling and capacity expansion, dataset portability is realized.
# 3) application scheduling for cloud data localization
The kubernetes scheduler obtains the data cache information of the node by interacting with the cache engine, and schedules the applications using the data to the nodes containing the data cache in a transparent manner to maximize the advantage of cache locality.
# Fluid architecture features
# 1. Fluid system architecture
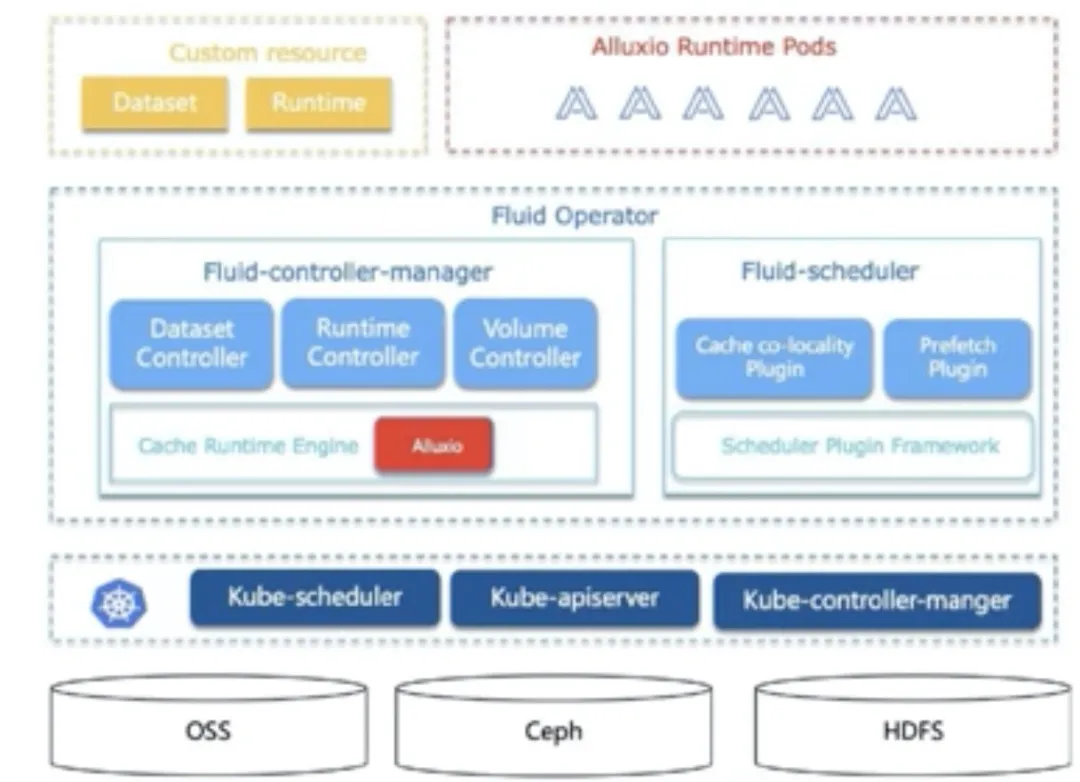
Fluid is a system built on k8s and has good compatibility with native k8s without modifying any code. As shown in the figure above, the user needs to define two CRDs: dataset and runtime. Dataset is the general definition of dataset, which is the k8s resource object provided by us. Yaml files need to be written to define where the dataset comes from and where it wants to be put; Runtime is the cache engine that stores these data sets. At present, it uses the open source distributed cache system alluxio. It should be noted here that when defining dataset and runtime, it usually has the same namespace, so as to achieve good binding.
Fluid operator is the core of the fluid project. It is divided into two parts. The first part is fluid controller manager, which contains many controllers; The other part is fluid scheduler. These two components complete the operation of scheduling. The work of fluid controller manager is to arrange the data, including three controllers. The three controllers are logically independent and can be used as a single process. However, in order to reduce the complexity, many controller functions are combined into one or more executable files during compilation, so they are also a process when they are actually running.
The dataset controller of the dataset is responsible for the lifecycle management of the entire dataset, including the creation of the dataset and which runtime to bind to.
The runtime controller is responsible for how data sets are scheduled and cached on the cloud native platform, on which nodes they should be placed, and how many copies they should have.
Volume controller: since fluid operates based on k8s, it needs to be connected with k8s. Here we use PVC (data persistent volume) protocol, which is a protocol of k8s local storage stack. It is widely used, and the connection between fluid and PVC is very smooth.
At the bottom is the cache runtime engine, which is the place to really complete the specific work of caching data.
The fluid scheduler in the right part of the figure mainly extends the k8s scheduler based on the specific information such as the defined dataset and runtime controller. The bread here contains two plugins:
Cache co locality plugin: what cache co locality plugin does is to schedule applications to the most appropriate node in combination with the information arranged in the previous data, and then try to enable users to read the information in the cache node.
Prefetch plugin: when the user cluster has not cached the incoming data and knows what kind of data the application must read, especially before the application scheduling and scheduling run, prefetch can be scheduled to cache the data from the lowest storage volume into the data cache, which can be triggered manually.
Further down is the standard k8s. K8s can connect different storage at the bottom layer, and the specific connection mode can be completed through k8s PVC. Because it is abstracted through alluxio, it can directly support the storage types supported by alluxio itself.
# 2. Functional concept of fluid
Fluid is not full storage acceleration and management, but application centric dataset acceleration and management.
Three important concepts :
Dataset: a dataset is a set of logically related data. The characteristics and optimization of different datasets are different. Therefore, datasets should be managed separately. Consistent file characteristics will be used by the same operation engine.
Runtime: the interface of the execution engine that truly realizes the capabilities of dataset security, version management and data acceleration, including how to create, how to manage the life cycle, etc., and defines a series of life cycle methods.
Alluxioruntime: from the alluxio community, it is an efficient implementation of the execution engine supporting dataset data management and caching. Through the above concept and architecture, the following functions are realized:
# 1) acceleration
- Observation: know the cache capacity easily.
- Portableand Scalable: adjust the cache capacity on demand.
- Co-locality: bring data close to compute, and bring compute close to data.
K8s provides this good observability. We can know our cache capacity and current status. Further, we can flexibly migrate and expand the cache, and then increase the cache capacity as needed. In addition, CO locality, that is, locality, will be fully considered in the process of expansion and migration. Data and computing are put together during scheduling and scheduling, so as to achieve the purpose of acceleration.
# 2) data volume interface, unified access to different storage
From the docking point of view, the data volume interface is supported to uniformly access different storage, and any data volume of k8s can be packaged into a fluid dataset for use acceleration.
# 3) isolation
The isolation mechanism enables the access to data sets to be isolated between different storage accelerators, and realizes permission control management.
# 3. How to use fluid
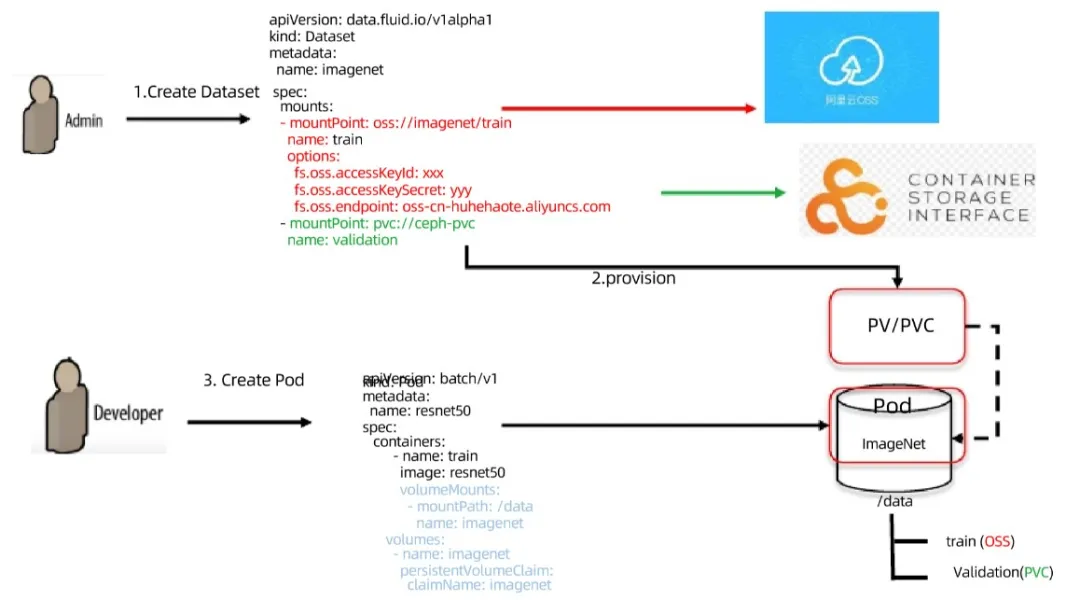
Taking the above figure as an example, users need to use data from two different places in the use scenario. Suppose one is from Alibaba cloud and the other is local storage CEPH. In fluid, we can easily describe such a dataset. By creating a custom k8s resource object dataset, the corresponding mountpoint can load two, alicloud and CEPH.
Once created, it can run. In this process, fluid will create a dataset and automatically turn it into a PVC. When the user needs to use this data, create a pod and associate the dataset with the running pod in the way of PVC mounting to access the data. Even pod doesn't know that the PVC background is running fluid, not other storage, such as NFS. The whole process and the principle behind it are transparent to users, which makes the docking of legacy programs very friendly.
# 4. How to check and observe dataset status

When running, there are many observable things. We define many metrics in dataset CRD. As shown in the figure above, the total cache capacity is 200GB, and the actual required capacity is 84.29gb. There is no need to expand the capacity, and the subsequent capacity can be expanded flexibly according to the actual demand. Through this tool, users can effectively query the storage capacity and usage, so as to achieve scalability.
# 5. Schedule jobs locally according to the dataset

It is also easy to arrange the application using the dataset. You only need to mount the fluid dataset into the application using the PVC mode, and then the k8s scheduler will interact with the fluid scheduler.
As shown in the example above, interact after mounting, and arrange the pod to run on the corresponding node according to the scheduling policy. When the k8s scheduler interacts with the fluid scheduler, you will see three nodes, two of which have alluxio cache nodes. We know that the classical k8s scheduling includes two very important stages, one is the filtering stage and the other is the optimization stage. In the filtering stage, the third node will be directly filtered out. In the optimization stage, some built-in optimization strategies can be used to select more appropriate nodes, such as the size of cache space, which has a lot of space for optimization in the future.
# Fluid performance evaluation
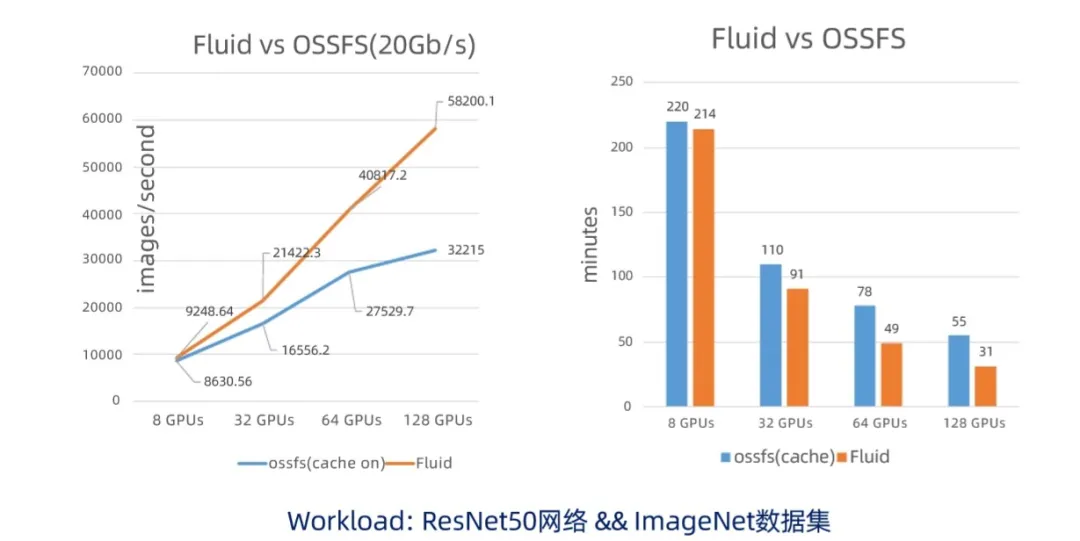
As shown in the figure above, we find that when the number of cards is increasing, using fluid will bring huge performance improvement. The essential reason is that when the number of GPUs becomes more and more (or the computing power of GPUs becomes stronger and stronger), accessing large-scale data has become the bottleneck of the whole training task. From the training results shown in the figure above, the end-to-end performance of fluid training is finally doubled, reducing costs and improving the user experience.

# Join the fluid community
To learn more about fluid, visit the fluid project GitHub address or view the fluid project home page. You are also welcome to join the fluid community communication nails group to deeply exchange project technology and its actual use scenarios with more users and developers.