
# Fluid: an important puzzle for big data and AI to embrace cloud Nativity

Thanks to the efficient deployment and agile iteration brought by containerization, as well as the natural advantages of cloud computing in resource cost and elastic expansion, the cloud native choreography framework represented by Kubernetes attracts more and more AI and big data applications to deploy and run on it. However, there has been a lack of a native component in the cloud native Computing Foundation (CNCF) to help these data intensive applications access data efficiently, safely and conveniently in the cloud native scenario.
How to drive big data and AI applications to run efficiently in cloud native scenarios is an important challenge with both theoretical significance and application value:
- On the one hand, to solve this problem, we need to consider a series of theoretical and technical problems, such as application collaborative choreography, scheduling optimization, data caching and so on;
- On the other hand, the solution of this problem can effectively promote the application of big data and AI in broad cloud service scenarios;
In order to systematically solve related problems, academia and industry cooperated closely and launched fluid open source cooperation project.
# What is Fluid?
Fluid is an open source cloud native infrastructure project. Driven by the separation of computing and storage, fluid aims to provide a layer of efficient and convenient data abstraction for AI and big data cloud native applications, abstracting data from storage, so as to achieve the following goals:
- Through data affinity scheduling and distributed cache engine acceleration, the integration between data and computing is realized, so as to accelerate the access of computing to data;
- The data is managed independently of the storage, and the resource is isolated through the namespace of Kubernetes to realize the data security isolation;
- The data from different storage is combined for operation, which has the opportunity to break the data island effect caused by the difference of different storage.
Through the data layer abstraction provided by Kubernetes service, data can be flexibly and efficiently moved, copied, expelled, transformed and managed between storage sources such as HDFS, OSS, CEPH, etc. and cloud native application computing on the upper layer of Kubernetes like fluid. The specific data operation is transparent to users. Users no longer need to worry about the efficiency of accessing remote data, the convenience of managing data sources, and how to help Kubernetes make operation and maintenance scheduling decisions. Users only need to directly access the abstracted data in the most natural way of Kubernetes native data volume, and all the remaining tasks and underlying details are handed over to fluid for processing.
Currently, fluid project mainly focuses on two important scenarios: data set choreography and application choreography. Data set choreography can cache the data of the specified data set to the Kubernetes node of the specified characteristics; Application choreography schedules the specified application to a node that can or has stored the specified data set. The two can also be combined to form a collaborative choreography scenario, that is, node resource scheduling considering data sets and application requirements.
# Why does cloud native need fluid?
There are natural differences in design concept and mechanism between cloud native environment and big data processing framework. Hadoop big data ecology, which is deeply influenced by Google's three papers GFS, MapReduce and BigTable, has believed in and practiced the concept of "mobile computing rather than data" since its birth. Therefore, in order to reduce data transmission, the design of data intensive computing framework and its application represented by spark, hive and MapReduce takes more consideration of data localization architecture. But with the change of the times, in order to give consideration to the flexibility of resource expansion and the cost of use, the architecture of separation of computing and storage is popular in the more emerging cloud native environment. Therefore, a component like fluid is needed in the cloud native environment to supplement the lack of data locality brought by big data framework embracing cloud native.
In addition, in the cloud native environment, applications are usually deployed in a stateless microservice mode, not centered on data processing; Data intensive frameworks and applications usually focus on data abstraction and carry out the assignment and execution of related computing jobs and tasks. When the data intensive framework is integrated into the cloud native environment, it also needs a data abstraction centric scheduling and allocation framework like fluid to work together.
Aiming at the problem that Kubernetes lacks intelligent perception and scheduling optimization of application data, and the limitation that the data choreography engine taking Alluxio as an example is difficult to directly control the cloud native infrastructure layer, fluid proposes a series of innovative methods, such as data application collaborative choreography, intelligent perception and joint optimization, And form a set of cloud native scene data intensive application efficient support platform
The specific architecture is shown in the figure below:

# Demonstration
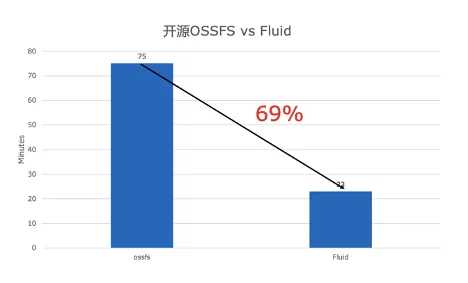
We provide a demo of the video to show you how to improve the speed of AI model training on the cloud through fluid. In this demo, using the same resnet50 test code, fluid acceleration has obvious advantages over native ossfs direct access in terms of training speed per second and total training time, and the training time is reduced by 69%.
Video presentation:

# Experience fluid?
Fluid needs to run in kubernetes v1.14 and above, and support CSI storage. The deployment and management of fluid operator is realized by the package management tool helm V3 on kubernetes platform. Before running fluid, make sure that helm is properly installed in the kubernetes cluster. You can refer to document, install and use fluid.