 |
Rainbow -- A Distributed and Hierarchical RDF Triple Store with Dynamic Scalability |
|
Rainbow -- A Distributed and Hierarchical RDF Triple Store with Dynamic Scalability |
Introduction: Rainbow adopts a distributed and hierarchical storage architecture that uses HBase as the scalable persistent storage and further combines a distributed memory storage to speedup query performance. Moreover, a hybrid RDF data indexing scheme well fitting the storage architecture is designed based on the statistical analysis of user query space. Also, a fault-tolerant mechanism in Rainbow is designed and implemented to assure successful query response.
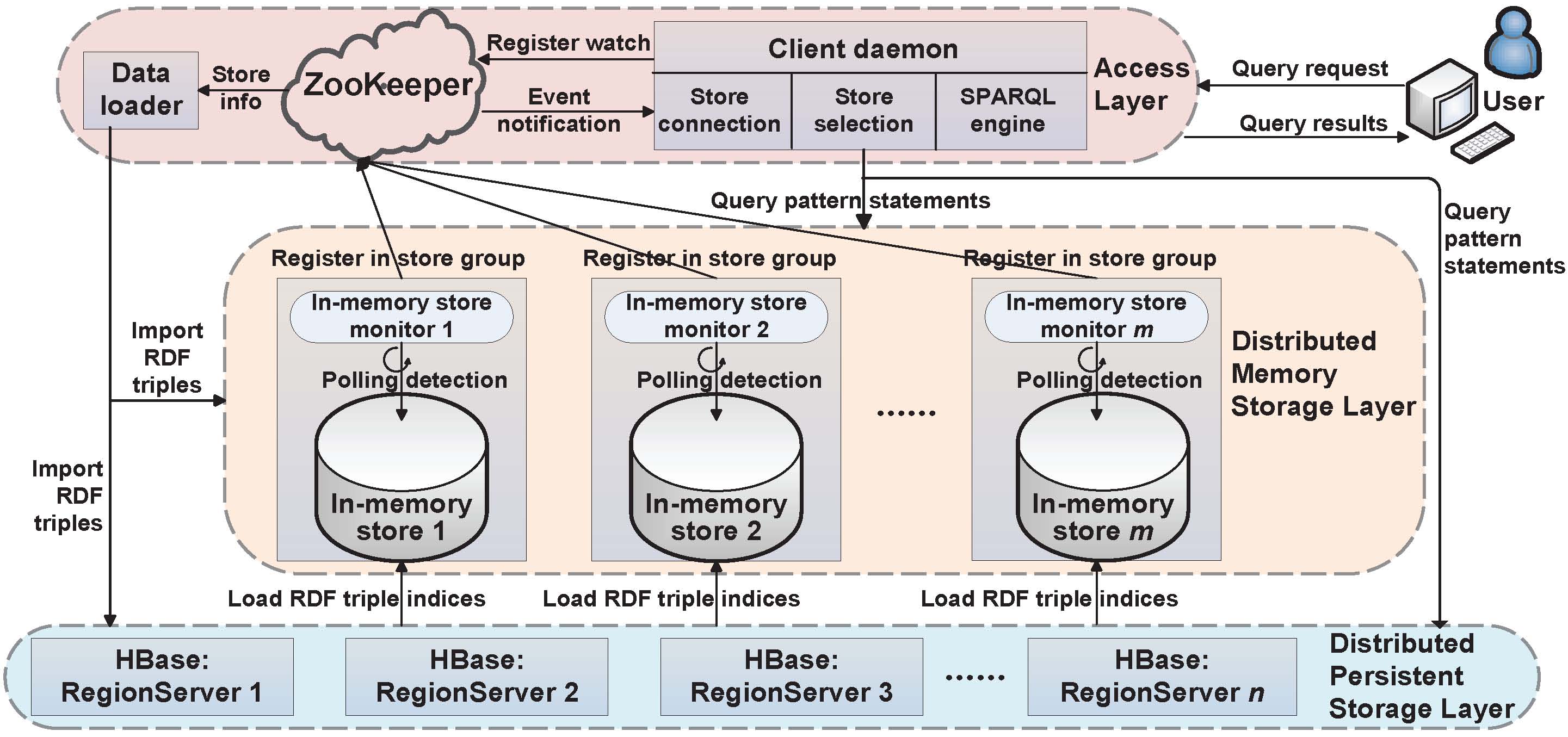
System Archtecture: The overview of Rainbow's system architecture is below.
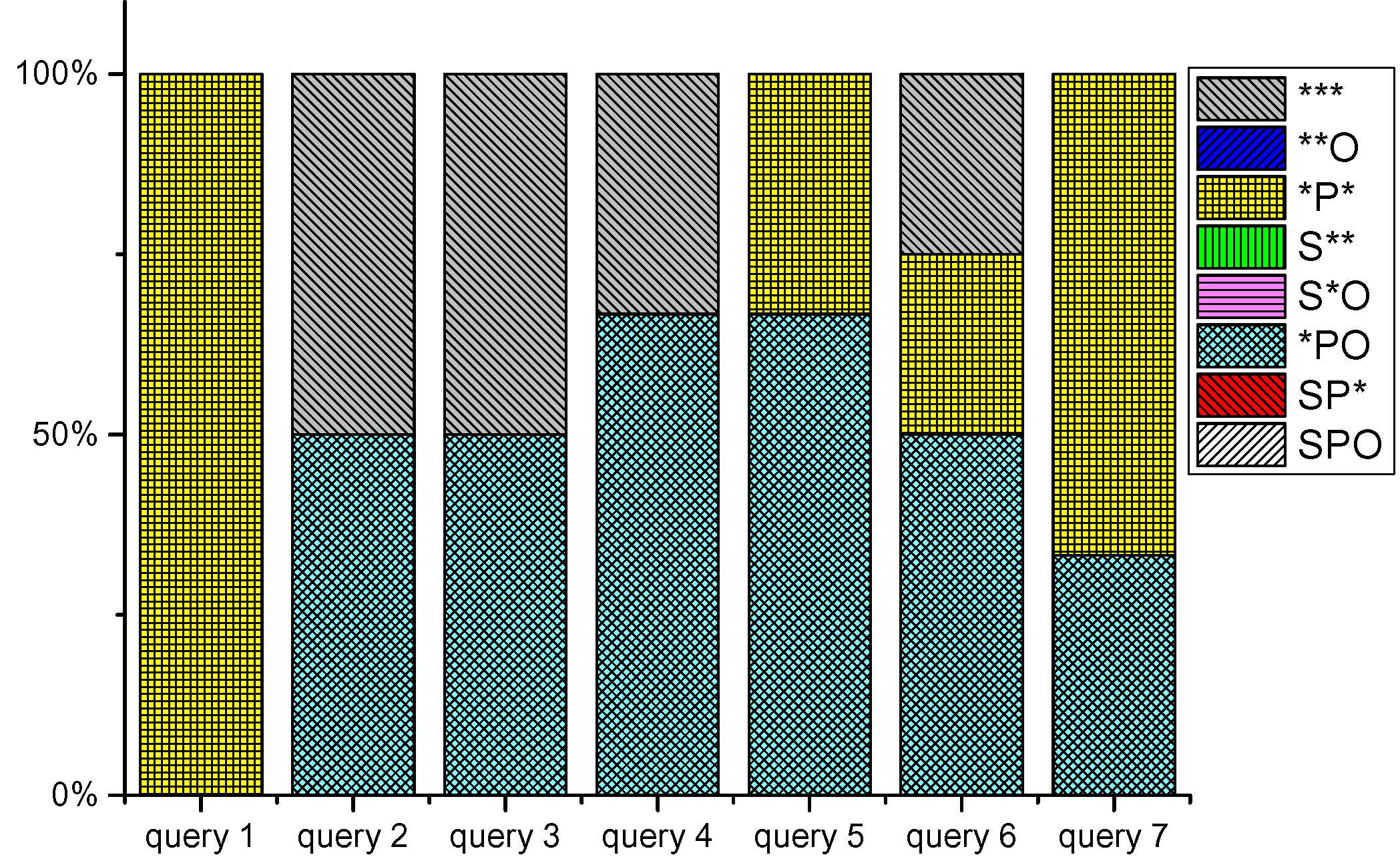
Query Space Analysis: To better decide what kinds of query pattern indices are more desirable to be stored in the distributed memory storage, we statistically analyze millions of real user queries and synthetic benchmark queries. The real user queries are got from the whole opened DBpedia query logs (around 22 million valid queries), and the synthetic benchmark queries are derived from some widely-used benchmarks, including LUBM, LongWell, SP2Bench and Berlin SPARQL Queries. The statistics of query patterns are shown below.
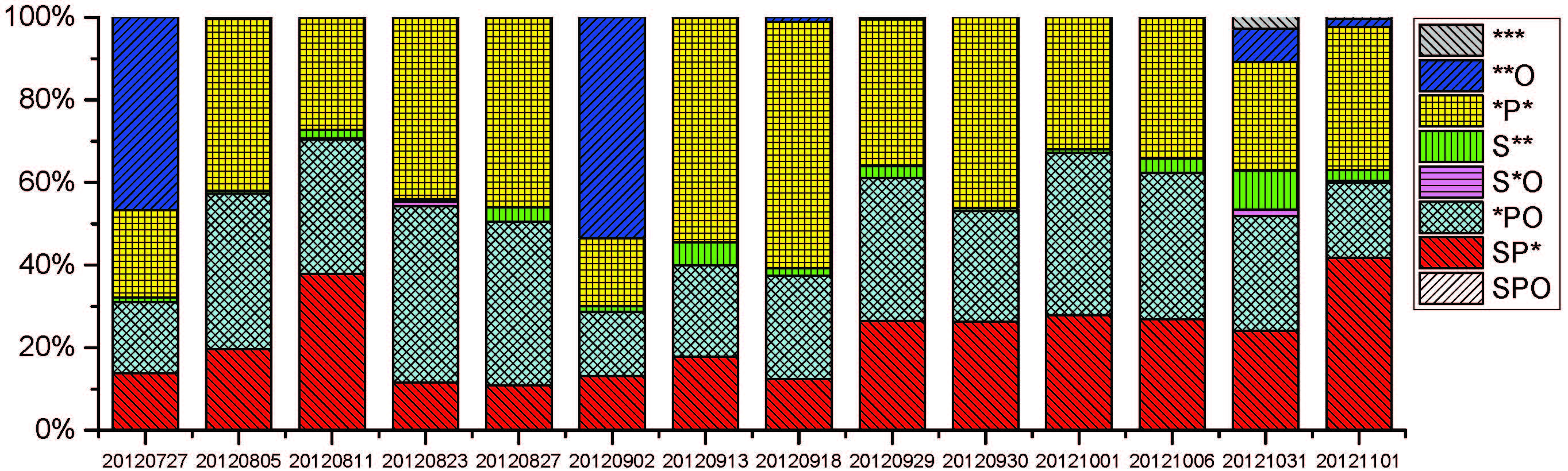
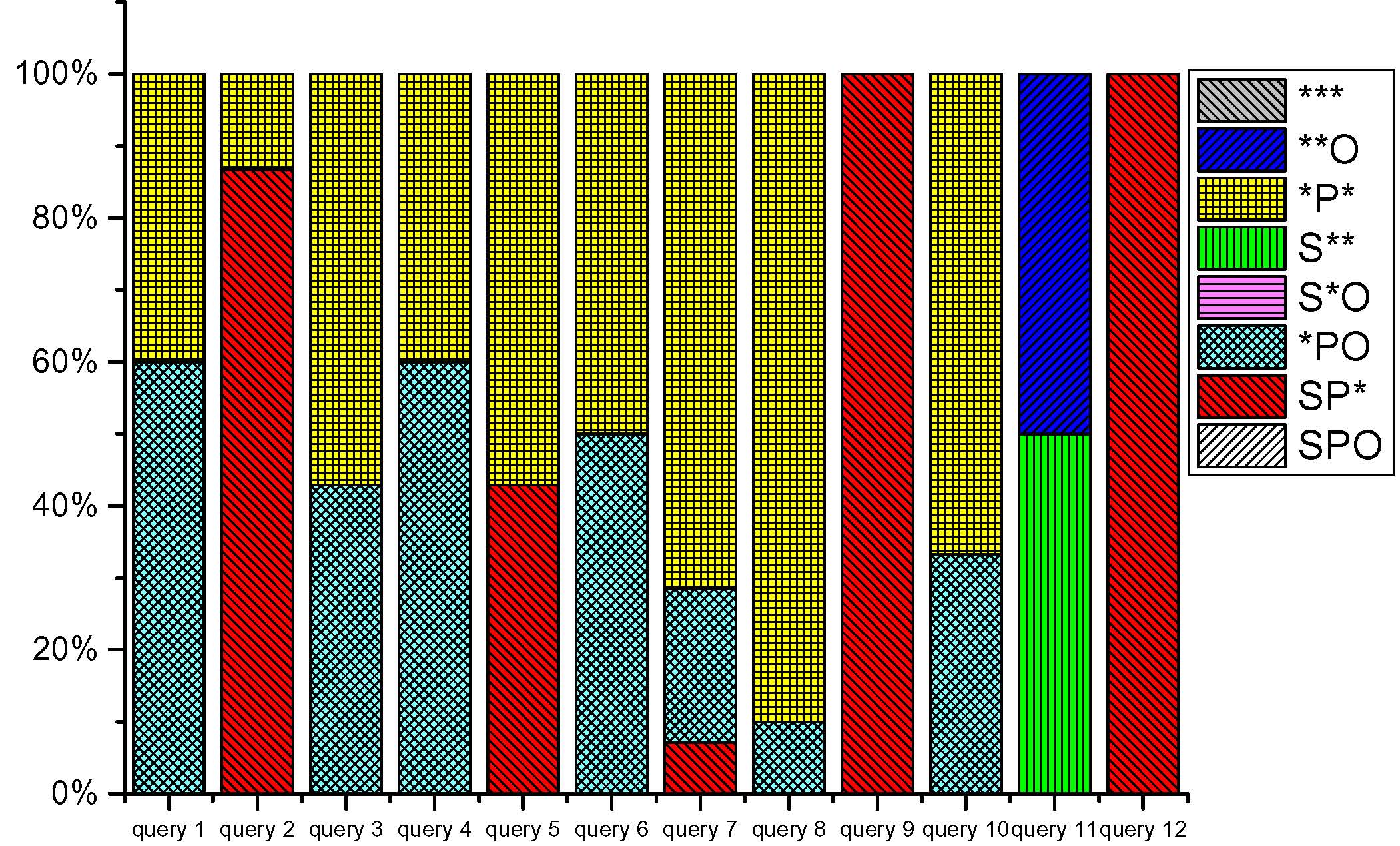
|

|
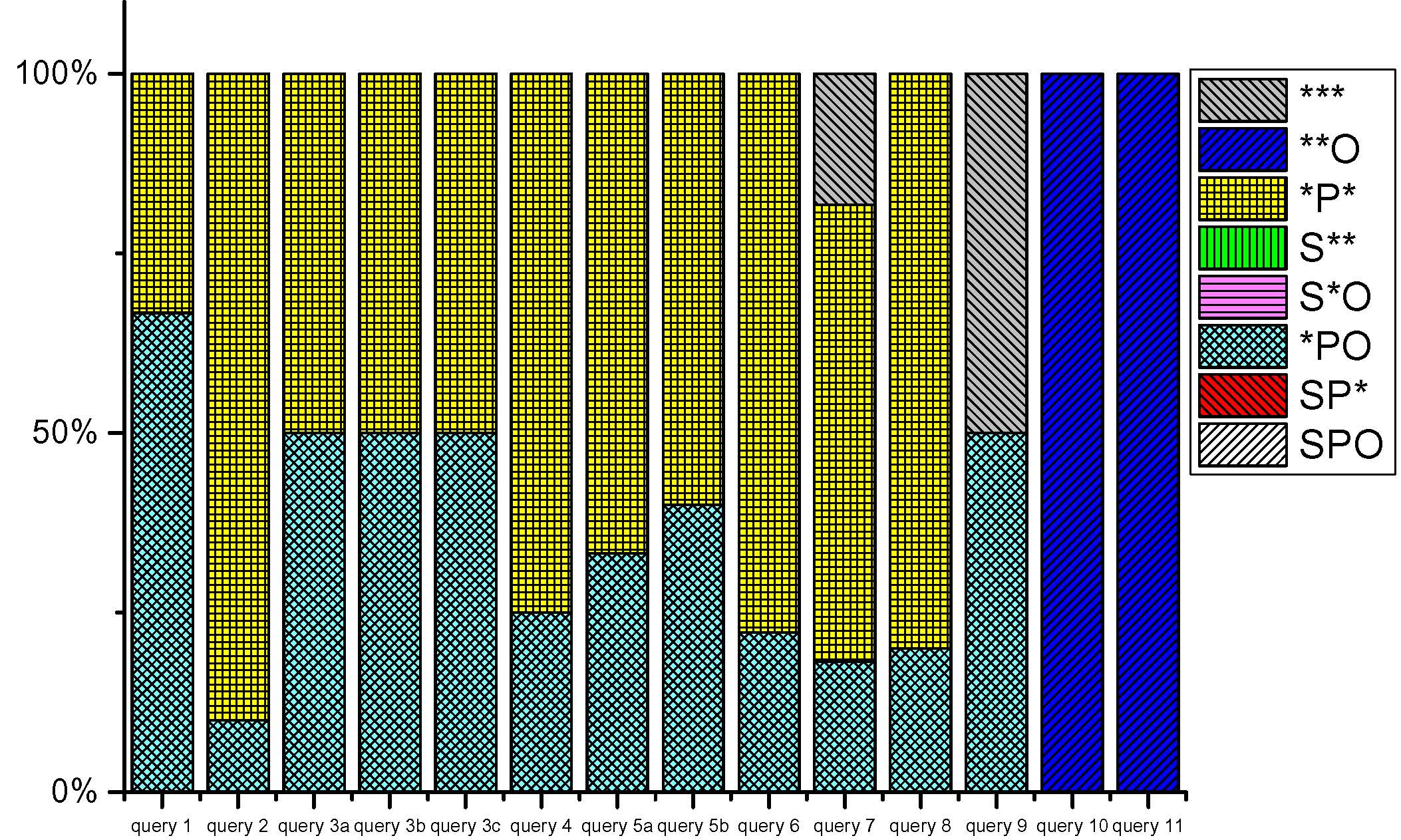
|
|
| Fig 2-b. Statistics of Berlin SPARQL Benchmark query patterns (extracted from here). | Fig 2-c. Statistics of LUBM query patterns (extracted from here). | Fig 2-d. Statistics of SP2Bench query patterns (extracted from here). | Fig 2-e. Statistics of LongWell query patterns (extracted from here). |
Indexing Scheme: Based on the statistical analysis above, we design a hybrid RDF data indexing scheme with its data placement (shown in Fig. 3) that well fits our distributed hierarchical storage architecture.

Benchmark: LUBM (the Lehigh University Benchmark) was used as the benchmark for test. LUBM has synthetic OWL and RDF data scalable to arbitrary size, as well as 14 extensional queries reflecting a variety of properties. In our experiments.
Triple Stores:
Rainbow: In our implementation, HBase (ver 0.94) is chosen as the distributed persistent storage. Redis (ver 2.4)
is the single-node in-memory store. The whole distributed memory
storage is made up of all these Redis stores to provide a unified
interface to applications. ZooKeeper (ver 3.3.6) is adopt as the distributed coordinator. The frontal SPARQL engine of Rainbow is built in OpenRDF framework currently. The source code of Rainbow is now available here. During
evaluation, the HBase cluster used in Rainbow is exactly the same as
that of Jena-HBase with totally same configuration. For Redis, we
adopted its default configuration.
Jena-HBase: (download from here). We adopted the Hybrid layout since the authors reported that it gave the best performance. JVM heap size was also set to 8GB.
SHARD: (download from here).
We used Hadoop 1.0.3. All the 17 nodes acted as TaskTrackers/DataNodes,
and another master node acted as JobTracker/NameNode. The Hadoop
configuration used 8 map/reduce slots per node and set each child's JVM
heap size to 8GB.
Sesame: (download from here).
Version 2.3.2. Tomcat 6.0 as the HTTP interface. selected the native
storage layout and set the SPOC, POSC, OPSC indices in the native
storage configuration. 8GB memory was also assigned to the JVM heap.
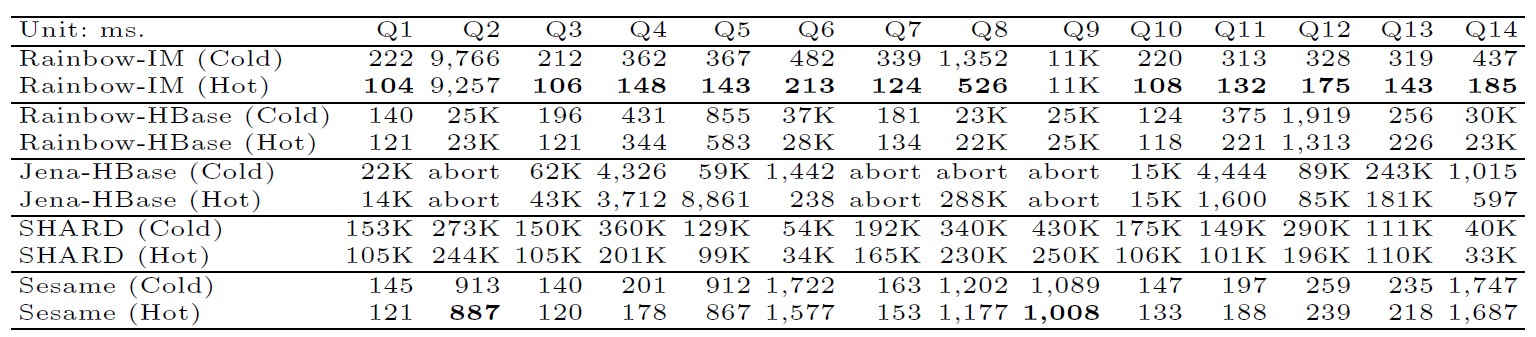
Query Perforamnce: We tested the performance of Rainbow and comparative systems on LUBM-10, LUBM-100 and LUBM-1000 w.r.t. their query execution time. For simplicity, the distributed memory storage in Rainbow is denoted as Rainbow-IM, and the underlying distributed persistent storage is denoted as Rainbow-HBase. For better demonstration, the query execution time on Rainbow-IM and Rainbow-HBase are listed separately. All the time presented here is the average of 10 runs of the queries. Also, both cold start (cold cache) and hot run performance is reported. The detailed results of the LUMB-10 are shown in Table below.
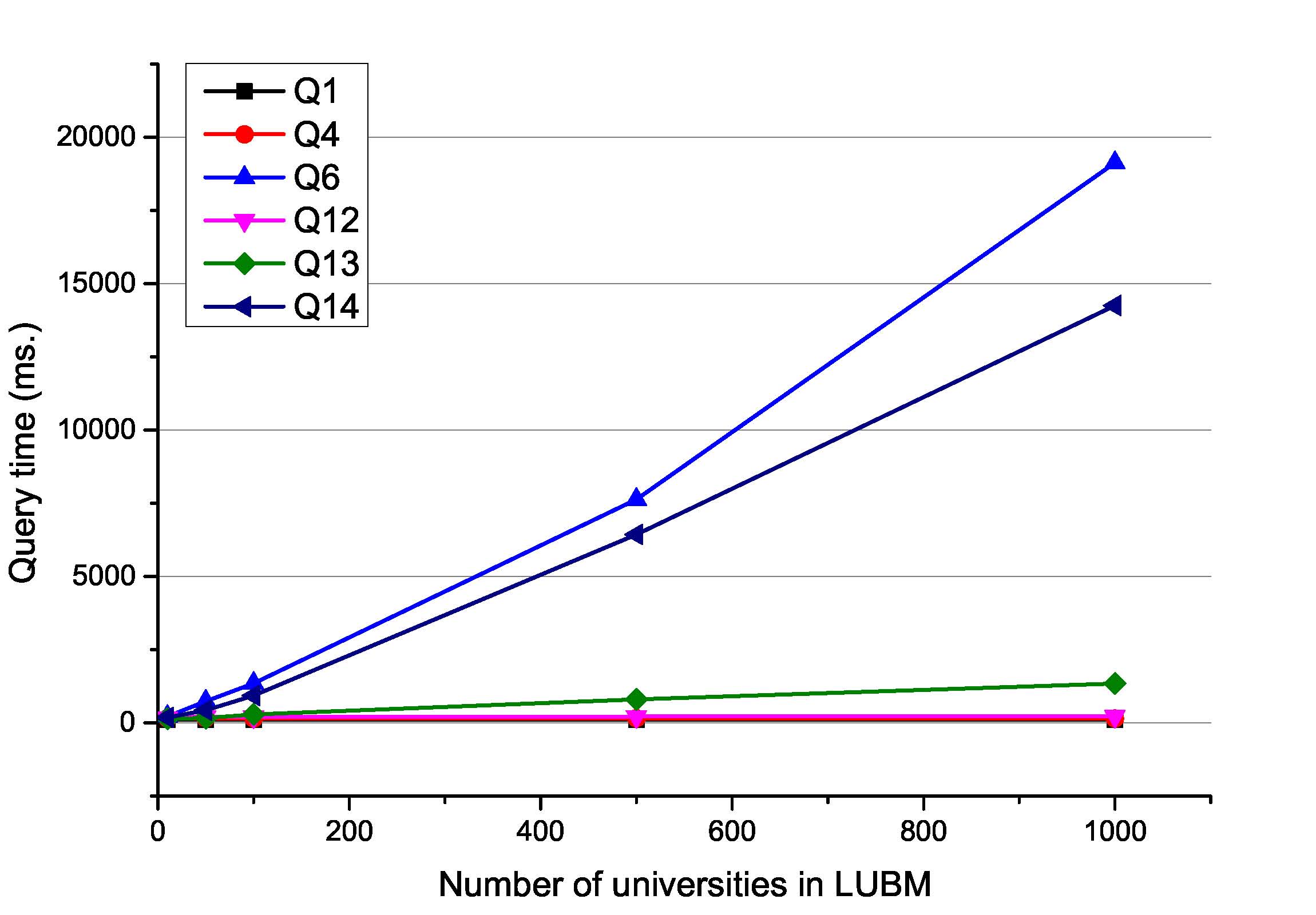
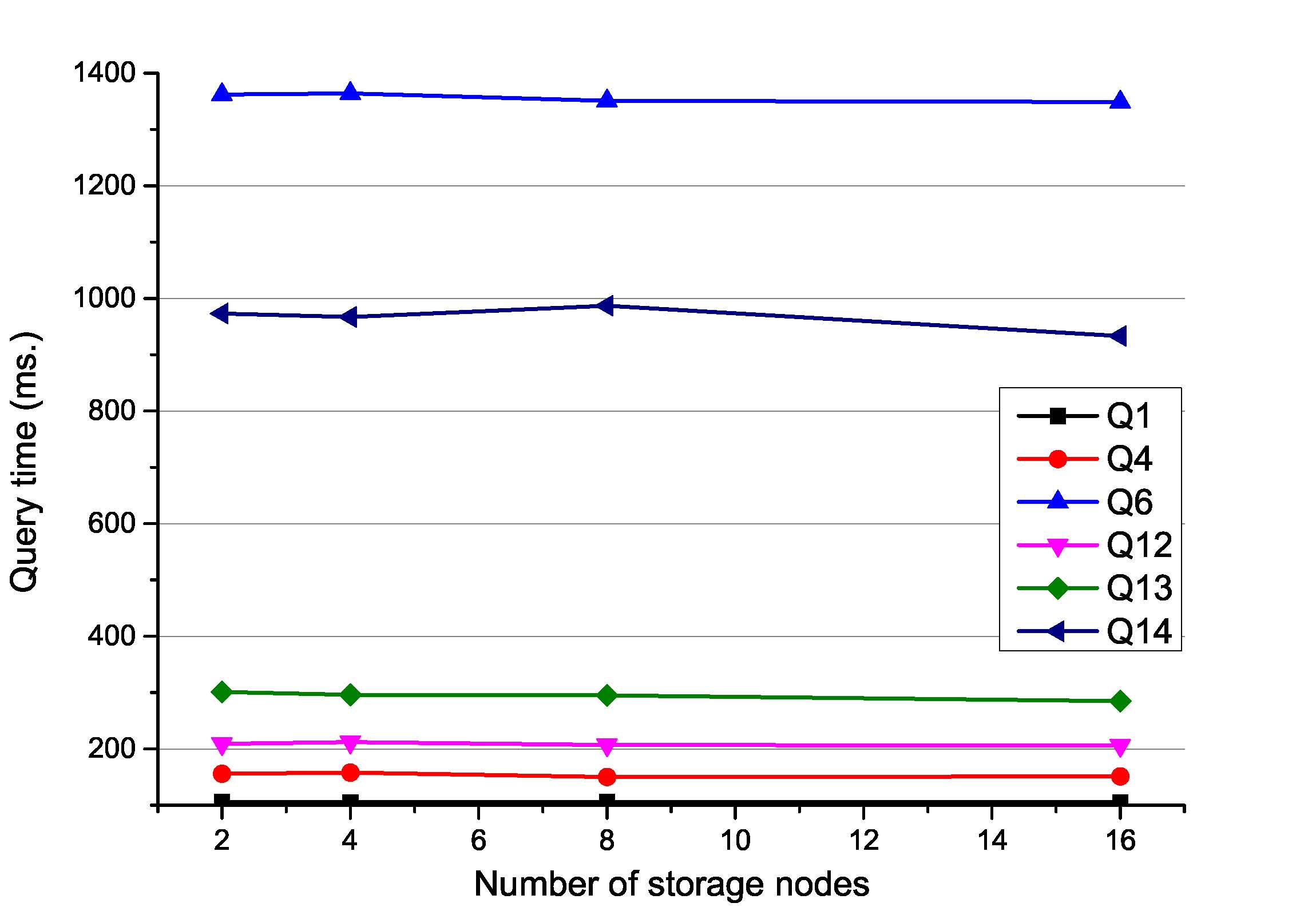
Scalability: We evaluated the scalability of Rainbow-IM by carrying out two experiments on a part of queries: (a) scaling the data amount while fixing the number of machines, and (b) scaling the number of machines while fixing the data size. The results are shown in the figures below.Please notice that, for all the queries, Rainbow-IM achieves stable performance regardless of increasing or decreasing the number of machines (shown in Fig. 7(b).). A possible reason for adding machines into Rainbow-IM is to enlarge the storage capacity of the distributed memory, which can potentially achieve more performance improvement when more data come to the system.
|
|
| Fig 5-a. Varying the amount of data in Rainbow-IM. | Fig 5-b. Varying the number of machines In Rainbow-IM. |
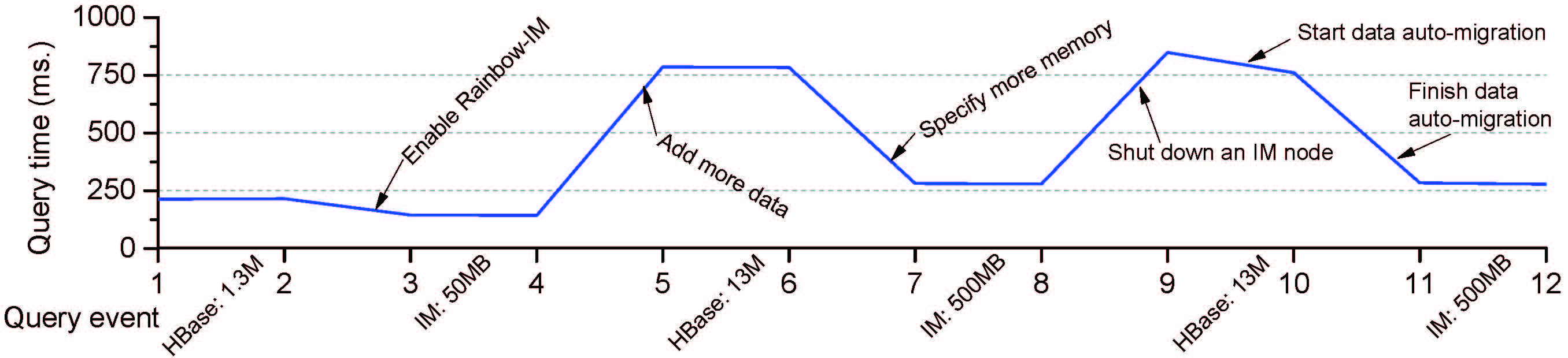
Dynamic and Fault Tolerant Features: We designed a simulating experiment to verify the dynamic scalability and fault tolerance features of Rainbow. The scenario is designed as follow: A user submits a sequence of queries (we chose the slow query Q13 here) to Rainbow; each submission is referred to as a query event. Rainbow keeps running without stopping.Initially, Rainbow-HBase held 1.3M triples while Rainbow-IM was disabled.
Contact: Rong Gu, Wei Hu, Yihua Huang